Replication
StorageOS replicates volumes across nodes for data protection and high availability. Synchronous replication ensures strong consistency for applications such as databases and Elasticsearch, incurring one network round trip on writes.
The basic model for StorageOS replication is of a master volume with distributed replicas. Each volume can be replicated between 0 and 5 times, which are provisioned to 0 to 5 nodes, up to the number of remaining nodes in the cluster.
In this diagram, the master volume D was created on node 1, and two replicas,
D2 and D3 on nodes 3 and 5.
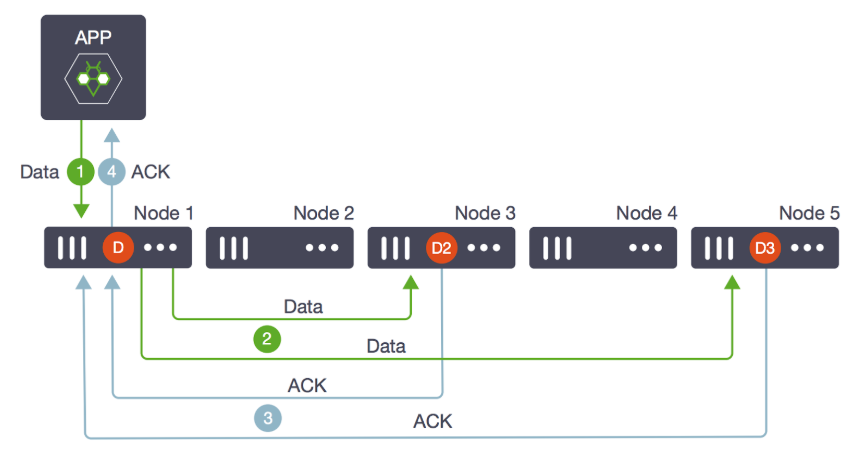
Writes that come into D (step 1) are written in parallel to D2 and D3
(step 2). When both replicas and the master acknowledge that the data has been
written (step 3), the write operation return successfully to the application
(step 4).
For most applications, one replica is sufficient (storageos.com/replicas=1).
All replication traffic on the wire is compressed using the lz4 algorithm, then streamed over tcp/ip to target port tcp/5703.
If the master volume is lost, a replica is promoted to master (D2 or D3
above) and a new replica is created and synced on an available node (Node 2 or
4). This is transparent to the application and does not cause downtime.
If a replica volume is lost and there are enough remaining nodes, a new replica is created and synced on an available node. While a new replica is created and being synced, the volume’s health will be marked as degraded.
If the lost replica comes back online before the new replica has finished synchronizing, then StorageOS will calculate which of the two synchronizing replicas has the smallest difference compared to the master volume and keep that replica. The same holds true if a master volume is lost and a replica is promoted to be the new master. If possible, a new replica will be created and begin to sync. Should the former master come back online it will be demoted to a replica and the replica will the smallest difference to the current master will be kept.
While the replica count is controllable on a per-volume basis, some environments may prefer to set default labels on the StorageClass.
Number of nodes
StorageOS replicas are distributed across available nodes. When a node fails, a new replica is provisioned and synced as described above. Failure to provision a new replica will eventually cause the volume to become read-only. StorageOS will re-attempt creation of the replica for 90 seconds. After that period, if the old replica is not available and a new replica cannot be provisioned, StorageOS cannot guarantee that the data is safe and stored on multiple nodes as requested by the user. It will therefore force the volume to be set to read-only.
To ensure that a new replica can always be created, an additional node should be available. To guarantee high availability, clusters using volumes with 1 replica must have at least 3 storage nodes. When using volumes with 2 replicas, at least 4 storage nodes, 3 replicas, 5 nodes, etc.
Minimum number of storage nodes = 1 (primary) + N (replicas) + 1
For an application to be able to use the volume normally, the volume needs to recover from a degraded state. This is achieved by having enough nodes on which to place the data, and triggering a remount of the volumes - i.e. deleting the Pod mounting the volume once it is in a healthy state.
Delta Sync
StorageOS implements a delta sync between a volume master and its replicas. This means that if a replica for a volume goes offline, that when the replica comes back online only the regions with changed blocks need to be synchronized. This optimization reduces the time it takes for replicas to catch up, improving volume resilience. Additionally, it reduces network and IO bandwidth which can reduce costs when running in public clouds.