Maintenance
Draining a node
Draining a node reschedules volumes to other nodes and marks the node as unschedulable.
-
If the volume does not have any replicas, a new replica will be created on a different node and promoted to master. The previous master will be removed.
-
If the volume has replicas, one will be promoted to master. The previous master will become a replica and be relocated to a different node.
-
If there are not enough available nodes, StorageOS will keep trying to evict all volumes while the node is in the drained state. Once a new node is added to the cluster, the volume will be moved automatically.
Performing a node drain will not remove the StorageOS mounts living in that node. Any volume mounted in that specific node will be evicted but still hold the StorageOS mount making the data transparently available to the client, with zero downtime.
To drain a node you can use the GUI (see the image below) or the StorageOS CLI
$ storageos node drain node01
node01
Cordoning a node
Cordoning a node marks the node as unschedulable without rescheduling any volumes running on the node. New volumes are unable to be scheduled nor can replicas be promoted on cordoned nodes.
To cordon a node you can use the StorageOS CLI
$ storageos node cordon node01
node01
Or using the GUI go to Nodes and use the cordon toggle.
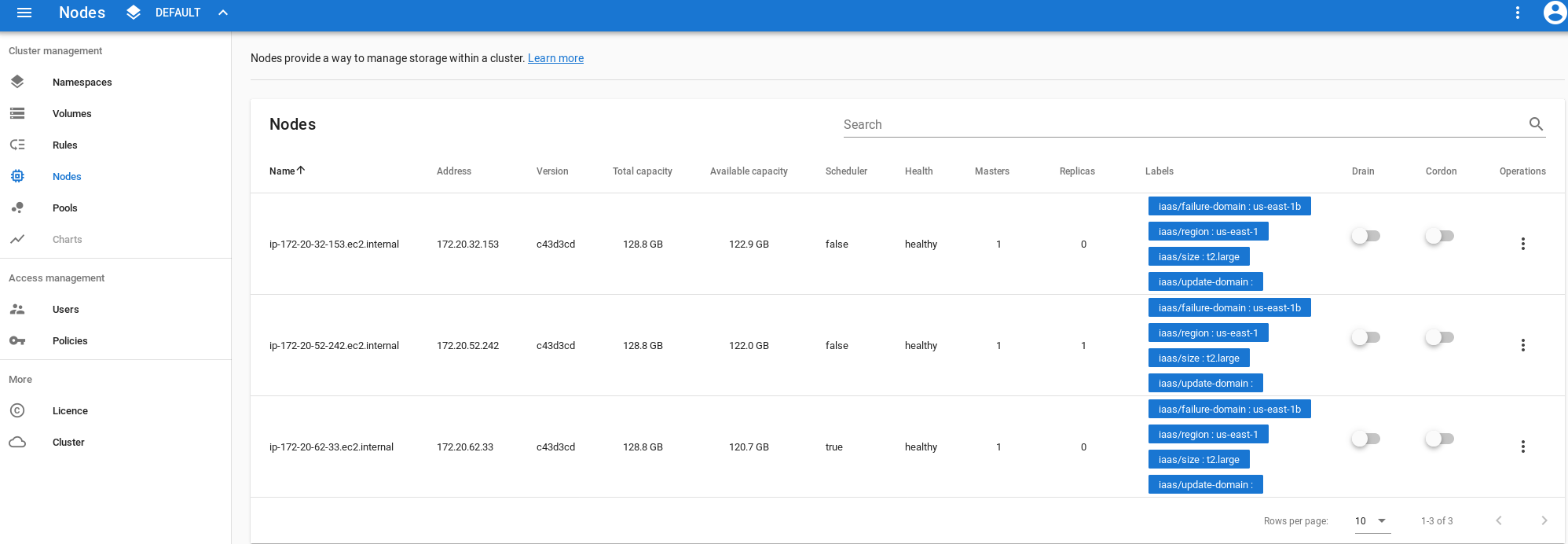
Cluster Maintenance Mode
Entering Cluster maintenance mode, or freezing a StorageOS cluster means that no volumes will be moved, or replicas promoted while the cluster is frozen.
In order to enter cluster maintenance mode you can either use the GUI or the StorageOS API.
Using the GUI go to Cluster and toggle Cluster Maintenance Mode on:
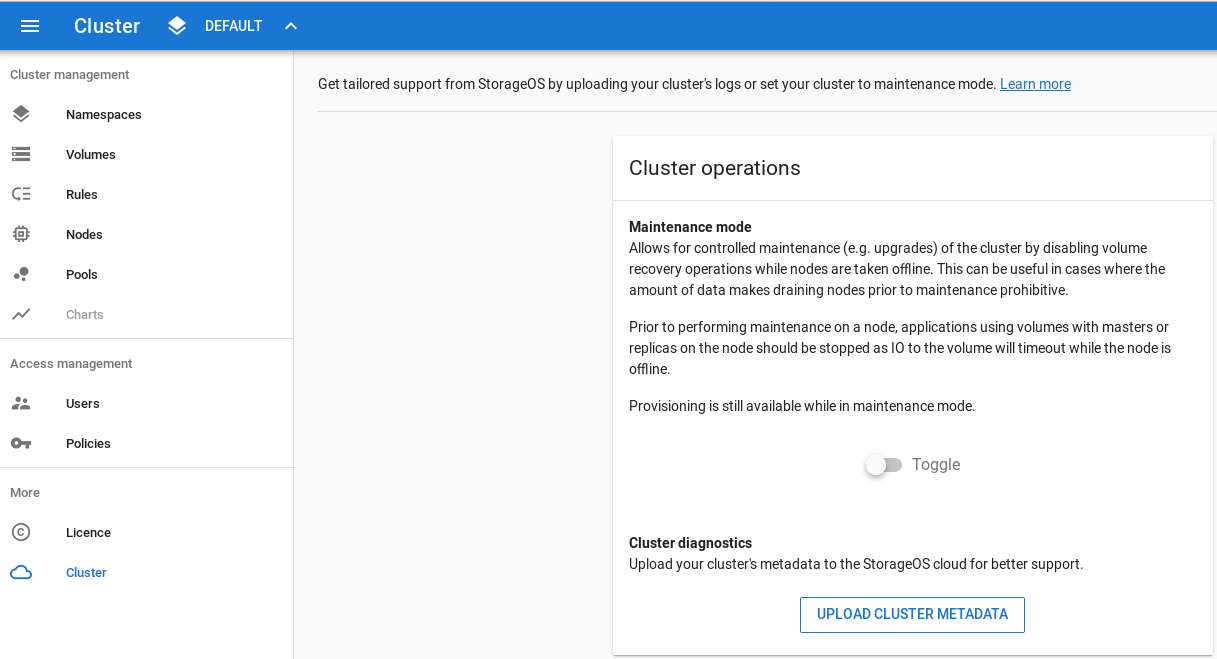
To enter Cluster maintenance mode using the API you can post to the following endpoint:
$ curl -u storageos:storageos -X POST 10.1.10.165:5705/v1/cluster/maintenance
{"enabled":true,"updatedBy":"storageos","updatedAt":"2018-11-13T15:57:34.605480403Z"}%
To leave Cluster maintenance mode using the API you can delete from the following endpoint:
$ curl -u storageos:storageos -X DELETE 10.1.10.165:5705/v1/cluster/maintenance
{"enabled":false,"updatedBy":"storageos","updatedAt":"2018-11-13T15:59:09.115797194Z"}%
Updates
Please see Updates operations for more information on how to apply StorageOS updates.