Cluster Topologies
StorageOS makes it possible for you to organise your cluster in multiple ways, depending on your priorities and needs. The approaches below are idealised representations of possible StorageOS clusters and can be mixed, modified and changed at execution time.
StorageOS performs file I/O over the network, which is how we ensure that your data is always available throughout your cluster. This also affords the user certain possibilities for organising your cluster, as we suggest below.
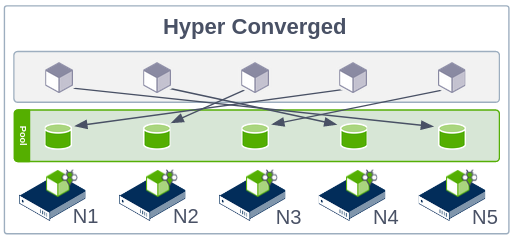
Hyperconverged Model
In this topology all nodes can store data and present data. This gives maximum flexibility to the StorageOS and Kubernetes schedulers, and maximum choice for pod placement. No matter how you deploy your workloads they will be able to store and access data on every node.
By default we place workloads locally where possible - this means that we default to a hybrid of the hyperconverged/high-performance models, maximising performance without extra effort.
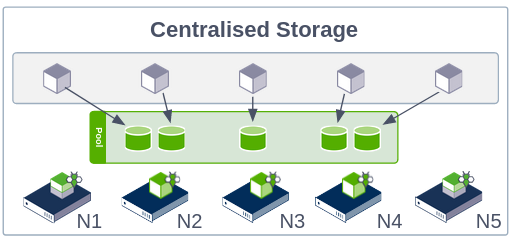
Centralised Storage Model
In this cluster topology volume data is placed on a particular subset of nodes,
while the remaining nodes in your cluster are set to computeonly, allowing
access to data hosted on other nodes, while consuming no storage themselves.
This model can be advantageous if, for example, you want to take advantage of
the hardware characteristics of particular nodes. A centralised storage model
can also help avoid problems with naive resource allocation, since storage
nodes and compute workloads can be kept apart.
This mode is also very suitable for elastic fleets with burstable workloads. A fleet can be expanded with many new machines for computing, while maintaining a central data store not impacted by rapid and repeated cluster scaling.
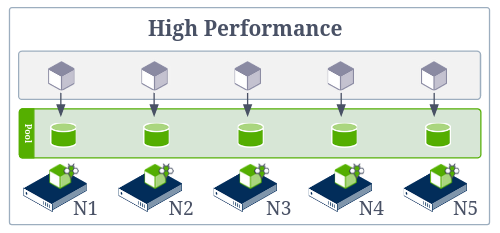
High Performance Mode
In this mode we co-locate pods with the volumes they are using in order to take advantage of the performance gains from running on the same node, while retaining the utility of orchestrators for managing app lifecycle.